

I. Development of Artificial Intelligence
Today, Artificial Intelligence (AI) has profoundly changed all aspects of human life and will continue to exert an increasingly important influence in the future. The concept of “Artificial Intelligence” was first proposed at an academic conference held at Dartmouth College in the United States in 1956, marking the beginning of a new era of AI research. Since then, AI has continuously developed and advanced through various challenges.
In 1986, Geoffrey Hinton, the father of neural networks, proposed the backpropagation (BP) algorithm suitable for Multilayer Perceptron (MLP) and used the Sigmoid function to achieve nonlinear mapping, effectively solving problems related to nonlinear classification and learning. In 1989, Yann LeCun designed the first convolutional neural network (CNN) and successfully applied it to handwritten postal code recognition tasks.
In the 1990s, Cortes and others proposed the Support Vector Machine (SVM) model, which rapidly developed into one of the representative techniques in machine learning and achieved great success in text classification, handwritten digit recognition, face detection, and bioinformatics. As we entered the 21st century, with the development of internet technologies and improvements in computer hardware systems, AI ushered in new and significant opportunities for development. Particularly since 2011, deep learning technologies represented by deep neural networks have developed rapidly, and humans have made many major breakthroughs on the road to AI.
II. Application of CPUs and GPUs in Artificial Intelligence
GPUs were originally used for image processing, but due to the emergence of high-performance computing requirements, GPUs, with their highly parallel hardware structure, significantly enhanced their parallel computing and floating-point computing capabilities, far exceeding those of CPUs. Since training deep neural networks involves very high computational intensity, training neural network models on CPUs often takes a long time.
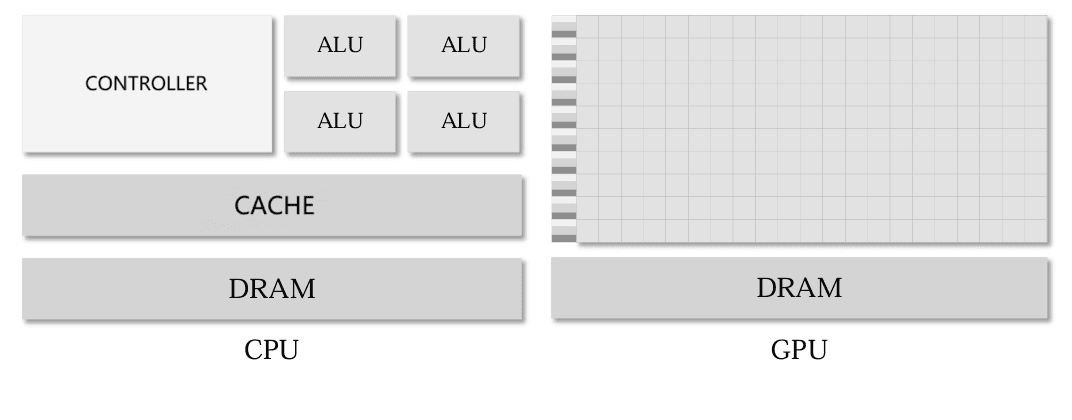
As shown in the diagram, a CPU is mainly composed of three major components: a controller, an arithmetic and logic unit (ALU), and a storage unit. The computing power of a CPU mainly depends on the number of computational cores in the ALU, which is large and heavy, making CPUs commonly used for processing serial programs with complex control logic to improve performance.
In contrast, a GPU consists of many Streaming Processors (SPs) and storage systems. SPs, also known as CUDA cores, are similar to ALUs in CPUs, and several SPs are organized into a Streaming Multiprocessor (SM). The numerous and smaller SPs in a GPU give it powerful parallel computing and floating-point processing capabilities, making it suitable for optimizing tasks that have simple control logic and high data parallelism, focusing on improving the throughput of parallel programs.
Graphics Processing Units (GPUs) have powerful single-machine parallel processing capabilities, particularly suitable for computationally intensive tasks, and have been widely applied in deep learning training. However, the computing power and storage of a single GPU are still limited, especially for many of today’s complex deep learning training tasks, where the training datasets are enormous. Training deep neural networks (DNNs) using a single GPU often requires a long time. For example, training ResNet-50 for 90 epochs on ImageNet-1K with a single Nvidia M40 GPU takes 14 days. Furthermore, in recent years, the scale of model parameters in deep neural networks has grown dramatically, leading to the emergence of many models with astonishing numbers of parameters. Since it is impossible to fit all the model parameters and activation values into a single GPU during the training of these large-scale DNN models, training such ultra-large-scale DNN models on a single GPU is not feasible.
With the rapid development of computer architecture, parallelism has become widespread in modern computer systems, which commonly have multi-core or multi-machine parallel processing capabilities.
Parallel computing architectures are typically divided into two types based on storage methods: shared memory architecture and distributed memory architecture.
In shared memory architectures, processors usually contain multiple computational cores and often support multi-threaded parallelism. However, due to storage and computational limitations, it is often not efficient to train machine learning models on a single computing device.
Multi-core cluster systems, which are widely used as multi-machine parallel computing platforms, have been extensively applied in the field of machine learning. These systems typically use multi-core servers as the basic computational nodes, which are interconnected via high-speed networks like Infiniband. In the field of deep learning training, single-machine multi-GPU (One Machine Multiple GPUs) and multi-machine multi-GPU (Multiple Machines Multiple GPUs) platforms have also become the mainstream for parallel training of neural networks.
The Message Passing Interface (MPI) is widely recognized as the ideal programming model on distributed memory systems, providing the communication support for parallel and distributed training of machine learning models. The essence of parallel training in machine learning models is to use multiple computing devices to collaboratively and simultaneously train the model. Typically, training involves first deploying the training data or model across multiple computing devices and then using these devices to collaborate and parallelize the model training.
Parallel training of machine learning models is generally suitable for two situations: (1) when the model can be loaded onto a single device, but the training data is vast, making it impossible to complete training within an acceptable time on a single device; (2) when the model parameters are so large that the entire model cannot be loaded onto a single device. The goal of parallel training is often to accelerate model training, where the total training time is determined by both the computation time per iteration or epoch and the convergence speed. The optimization algorithm used in model training determines the convergence speed, and using an appropriate parallel training mode can speed up the computation of each iteration or epoch. In parallel training, data is first distributed to different computing devices.
Depending on the method of data distribution, the parallel training mode of a model can be divided into data parallelism, model parallelism, and pipeline parallelism.
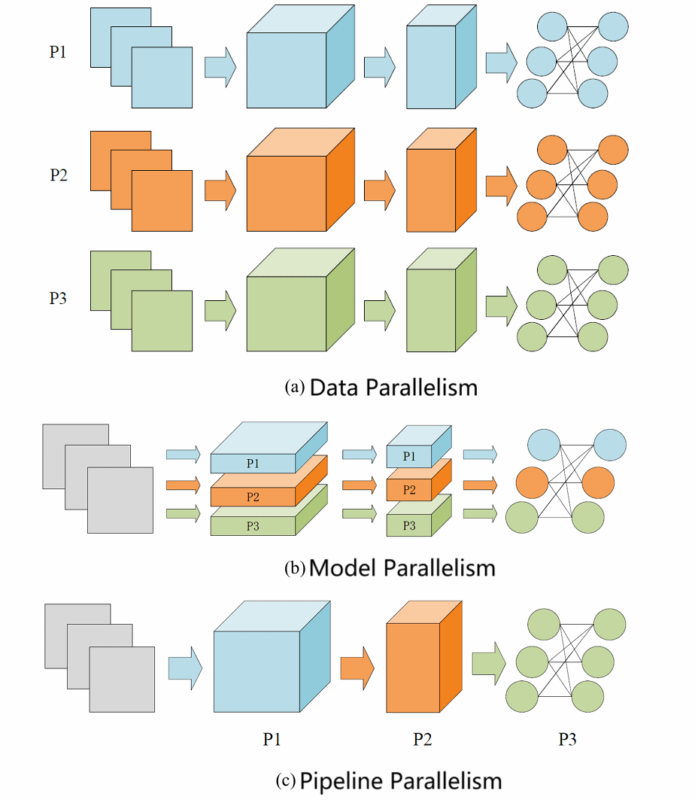
The diagram above illustrates the three parallel training modes. Data Parallelism is the most popular method for DNN parallel training today. Many popular deep learning frameworks like TensorFlow, PyTorch, and Horovod offer easy-to-use APIs to support data parallelism.
As shown in (a), in data parallelism, each computing device holds all of the same model parameters and is assigned different batches of training data. After gradients from all computing devices are summed using collective communication operations like a parameter server or Allreduce, the model parameters are updated. A deep neural network typically consists of many layers of neurons stacked together, with each layer forming fully connected layers, convolutional layers, and other types of operators.
Traditional model parallelism involves dividing the neural network model into different parts horizontally and distributing them across multiple computing devices. As shown in (b), model parallelism splits the data flow graph of different operators and stores them across multiple devices, ensuring these operators act on the same batch of training data. Since this splitting divides operators horizontally, model parallelism is also referred to as operator parallelism or horizontal parallelism.
When a neural network model is vertically split by layer, model parallelism can further be categorized as pipeline parallelism. As shown in (c), pipeline parallelism divides the neural network into multiple stages, each consisting of multiple consecutive layers. These stages are distributed across different computing devices, which then train the model in a pipeline fashion. The forward propagation of the neural network starts from the first device and propagates forward until the last device completes the forward pass.
Subsequently, the backpropagation process begins from the last computing device and propagates backward until the first device completes the backward pass. In algorithm acceleration, current research primarily focuses on utilizing the computational capabilities of different platforms. The main acceleration platforms include Application-Specific Integrated Circuits (ASICs), Field-Programmable Gate Arrays (FPGAs), and Graphics Processing Units (GPUs). Among them, ASICs are highly customized, have long design cycles, and are difficult to respond to rapidly changing market demands. FPGAs, being programmable integrated circuit chips, offer relatively high flexibility and are quicker to deploy than ASICs, with lower costs. However, due to their nature as hardware parallel designs, FPGAs are not as versatile or cost-efficient as GPUs.
III. What is CUDA?
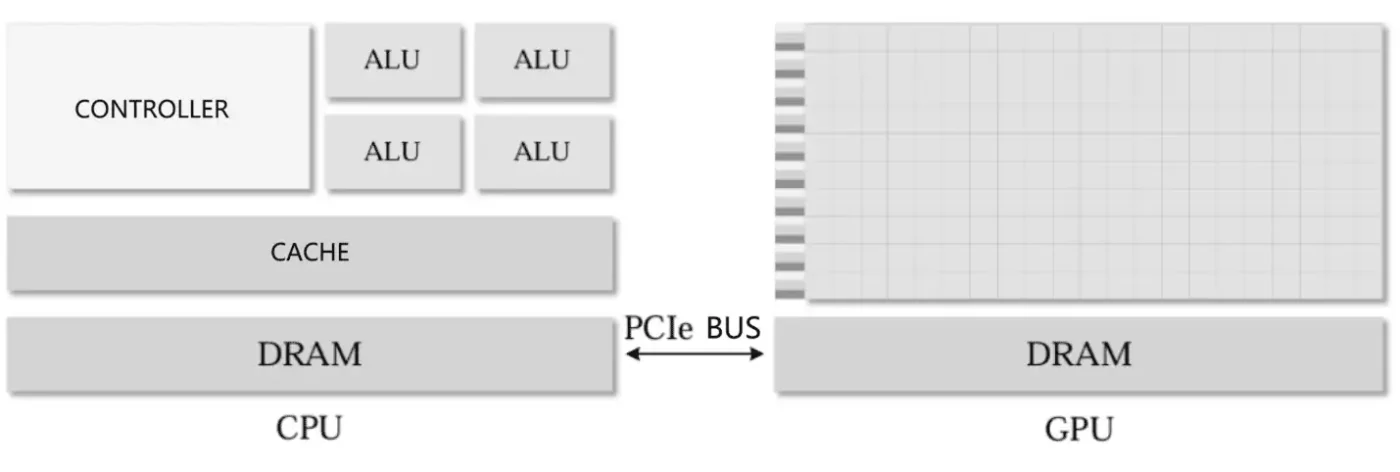
CUDA (Compute Unified Device Architecture) is a programming model introduced by NVIDIA, which provides interfaces that allow developers to accelerate general-purpose computations using GPUs. This makes it easier to build GPU-based applications and fully leverage the GPU’s efficient computational and parallel capabilities. CUDA supports various programming languages such as C/C++, Python, etc., making parallel algorithms more feasible. Since GPUs cannot operate as independent computing platforms, CUDA programming requires collaboration with the CPU to form a heterogeneous computing architecture, where the CPU is referred to as the host, and the GPU is referred to as the device.

The GPU is primarily responsible for computation, accelerating tasks assigned by the CPU through its parallel architecture and powerful computing power. Using the CPU/GPU heterogeneous architecture and CUDA C, GPU resources can be fully utilized to speed up certain algorithms. A typical GPU architecture is shown below, where both the GPU and CPU main memory are implemented using DRAM, and their storage structures are quite similar. However, CUDA presents GPU memory in a better way to programmers, increasing the flexibility of GPU programming.
The process of implementing parallel optimization in CUDA programs involves three main steps:
- Store data in the host memory, initialize it, allocate device memory, and load the host data into the device memory.
- Call kernel functions to execute parallel algorithms on the device. A kernel function refers to a program running on the GPU.
- Unload the final result of the algorithm from the device memory back to the host and then release all memory from both the host and device.
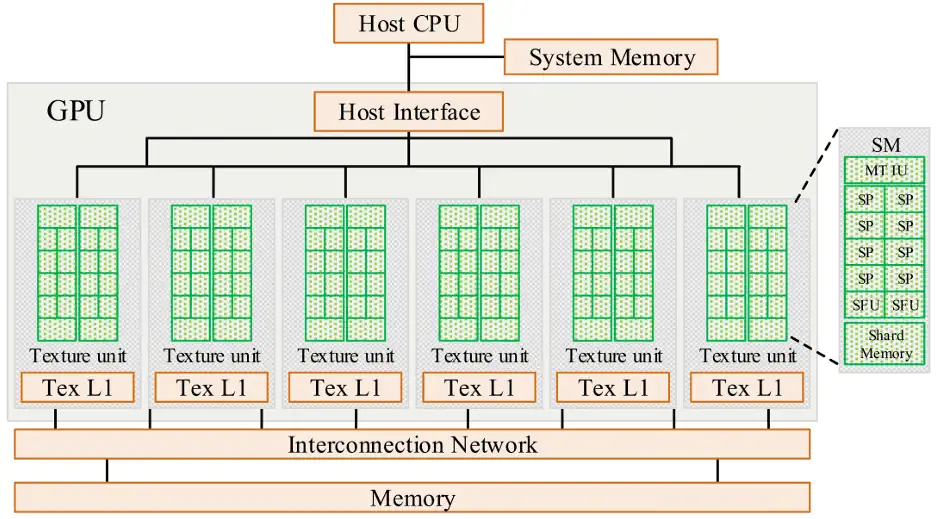
The core component of the GPU is the Streaming Multiprocessor (SM), also known as the “big core” of the GPU. A GPU device contains multiple SM hardware units, and each SM consists of CUDA cores, shared memory, and registers. The CUDA core is the fundamental processing unit of the GPU, and specific instructions and tasks are processed by these cores. In essence, when the GPU executes parallel programs, multiple SMs are used to handle different threads simultaneously. Shared memory and registers are the most important resources inside the SM, and the parallel capability of the GPU largely depends on the resource allocation inside the SM.
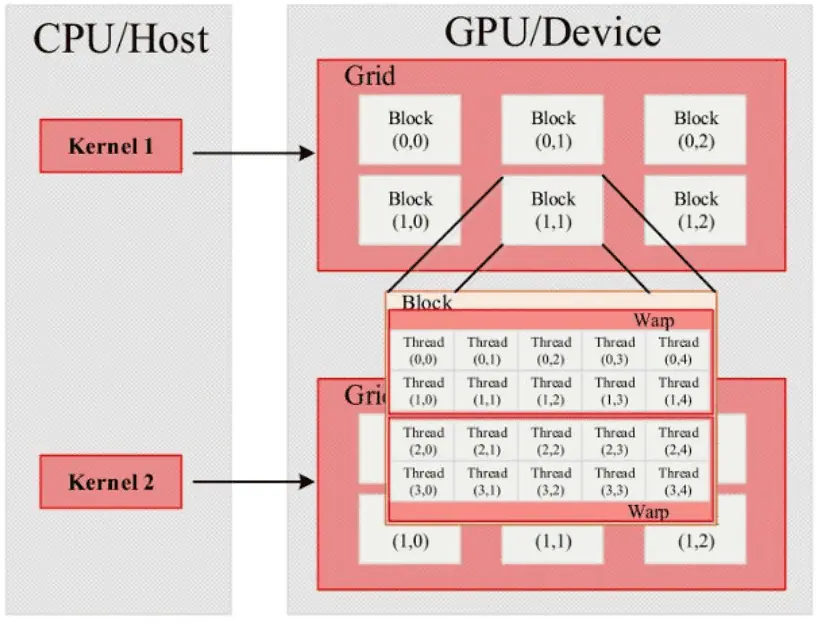
In CUDA architecture, Grid, Block, and Thread are three essential software concepts. Threads are responsible for executing specific instruction tasks, thread blocks consist of multiple threads, and grids consist of multiple thread blocks. The number of threads and thread blocks can be set according to the program’s design.
When the GPU executes a kernel function, it uses a grid as the overall execution unit, dividing it into multiple thread blocks and then assigning these thread blocks to SMs for computation tasks. The GPU memory structure, as shown below, mainly consists of registers located inside the Streaming Processor (SP), shared memory on the SM, and global memory on the GPU board.

In the CUDA unified programming model proposed by NVIDIA, the entire GPU’s threads are managed by a Grid, where each Grid contains multiple thread blocks, and each Block can be further divided into several thread groups called Warps. A Warp is the smallest unit of thread management in the GPU, where threads inside a Warp execute using the Single Instruction, Multiple Threads (SIMT) model. The basic structure of CUDA thread management is shown below.
The unique architecture of the GPU and its powerful parallel programming model provide it with distinct performance advantages in parallel computing and memory access bandwidth. Compared to traditional CPU architectures, GPUs have several unique advantages:
- High parallelism and strong computing power.
Compared to CPU architectures, GPUs integrate more parallel computation units, enabling outstanding performance in parallel computing. Furthermore, their theoretical peak computational power far exceeds that of CPUs from the same period. For example, the current NVIDIA A100 GPU achieves inference speeds up to 249 times faster than two Intel Xeon Gold 6240 CPUs when performing Bert inference tasks. - High memory bandwidth.
To match the GPU’s powerful parallelism, the GPU is equipped with a large number of memory controllers and high-performance internal interconnects, leading to higher memory access bandwidth. The current memory bandwidth of the NVIDIA A100 GPU reaches 1.94 TB/s, while the Intel Xeon Gold 6248 CPU of the same period only achieves 137 GB/s. Graph processing, due to its high computation-to-memory ratio, frequent computation, and small individual computation tasks, naturally aligns with the hardware characteristics of the GPU.
IV. Conclusion
With the continuous progress of deep learning (DL), various deep neural network (DNN) models have emerged. DNNs not only greatly surpass traditional models in terms of accuracy but also bring new breakthroughs to many fields due to their excellent generalization ability.
As a result, Artificial Intelligence (AI) technology is rapidly being applied in various industries. Today, whether it is in the edge devices of the Internet of Things (IoT) or in the high-performance servers of data centers, DNNs are everywhere. The development of AI is inseparable from the improvement in computational power, and thus the demand for high-performance GPUs will continue to rise.
References:
(1) Yang Xiang, Research on Parallel Inference Acceleration Technology of Deep Learning Models [D].
(2) Zheng Zhigao, Key Technology Research on GPU-based Graph Processing Algorithm Optimization [D].
(3) Guan Lei, Key Technology Research on Parallel Training of Machine Learning Models [D].
(4) Xue Shenglong, Research on Rapid Generation of Radar Clutter and GPU Implementation [D].
(5) Han Jichang, Design and Implementation of SM3 and SM4 National Encryption Algorithms Based on CUDA [D].
Related:

Disclaimer:
- This channel does not make any representations or warranties regarding the availability, accuracy, timeliness, effectiveness, or completeness of any information posted. It hereby disclaims any liability or consequences arising from the use of the information.
- This channel is non-commercial and non-profit. The re-posted content does not signify endorsement of its views or responsibility for its authenticity. It does not intend to constitute any other guidance. This channel is not liable for any inaccuracies or errors in the re-posted or published information, directly or indirectly.
- Some data, materials, text, images, etc., used in this channel are sourced from the internet, and all reposts are duly credited to their sources. If you discover any work that infringes on your intellectual property rights or personal legal interests, please contact us, and we will promptly modify or remove it.