

News on March 11th indicates that, according to a recent survey, a large number of AI professionals are planning to switch from NVIDIA to the AMD Instinct MI300X GPU.
Jeff Tatarchuk, co-founder of TensorWave, revealed that they conducted an independent survey covering 82 engineers and AI professionals. Among them, about 50% of respondents expressed confidence in the AMD Instinct MI300X GPU because, compared to NVIDIA’s H100 series products, the MI300X not only offers better value for money but also has a sufficient supply, avoiding the problem of tight inventory. Jeff also mentioned that TensorWave would adopt the MI300X AI accelerator. This is undoubtedly good news for AMD, as its Instinct series products have been at a disadvantage in market share compared to NVIDIA’s competitors.
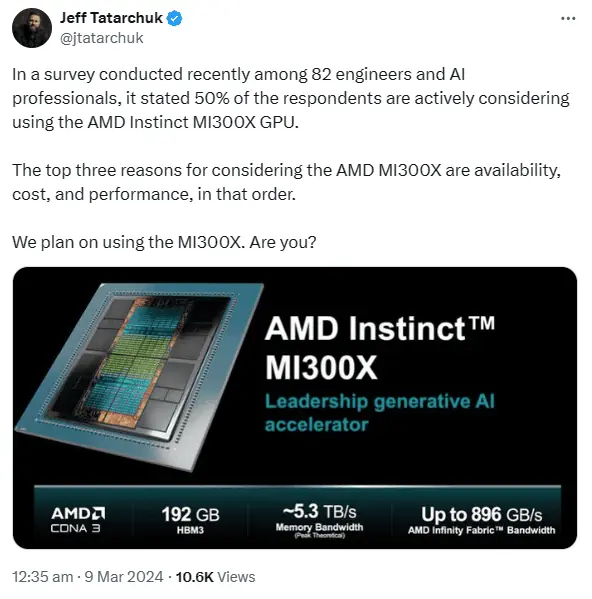
According to News, the AMD Instinct MI300X AI accelerator is built on the CDNA 3 architecture, using a hybrid of 5nm and 6nm process technology, with up to 153 billion transistors (MI300X model). There is also a significant improvement in storage, with the MI300X’s HBM3 capacity 50% higher than the previous generation’s MI250X (128 GB).
So, can this chip truly threaten NVIDIA’s position in the era of large models?
Looking at the hardware specifications, the Instinct MI300X GPU chip indeed has significant advantages. It adopts a design with multiple GPU chiplets, which, together with another 4 I/O and HBM memory chiplets, form an integrated system of 12 5nm chiplets. In comparison, NVIDIA’s H100 accelerator has only one GPU core and 80GB of HBM2e memory. AMD officially states that the HBM2e memory of the Instinct MI300X GPU chip is 2.4 times that of NVIDIA’s H100 SXM, and its memory bandwidth is 1.6 times greater. Even compared to a single GPU on NVIDIA’s Grace Hopper super chip, this chip still has certain advantages.
From the software platform perspective, the Instinct MI300X GPU chip has also made significant progress. It is based on AMD’s ROCm 5 platform, providing low-level libraries, compilers, development tools, and runtime, supporting mainstream AI frameworks such as PyTorch, TensorFlow, and ONNX. Moreover, AMD has reached a cooperation agreement with the PyTorch Foundation, starting from PyTorch 2.0, any AI model or application developed with PyTorch can run natively on the Instinct accelerator. This is a huge attraction for many developers and cloud service providers using PyTorch.
Finally, looking at the market layout, the Instinct MI300X GPU chip also has a promising future. It can meet the needs of various scenarios such as high-performance computing, cloud computing, and edge computing, and provide specialized solutions for large model training. AMD also released the AMD Instinct platform, which has eight MI300X GPU chips, adopts the industry-standard OCP design, and provides a total of 1.5TB of HBM3 memory. Su Zifeng stated that the MI300X GPU chip and the eight-GPU chip Instinct platform will be sampled in the third quarter of this year and officially launched in the fourth quarter.
We can see that the AMD Instinct MI300X GPU chip is a very powerful and innovative AI/DL accelerator product, with strengths in hardware specifications, software platforms, and market layout that are not inferior to NVIDIA. Although NVIDIA is still the dominator in the GPU chip market, AMD has shown a strong challenging posture, and the future competition will be more intense and exciting. We look forward to more surprises and innovations from NVIDIA and AMD’s chips in the future.
Compared to NVIDIA’s H100, the MI300X has the following advantages:
- 2.4 times more memory capacity
- 1.6 times more memory bandwidth
- 1.3 times higher FP8 performance (TFLOPS)
- 1.3 times higher FP16 performance (TFLOPS)
- Up to 20% more performance in 1v1 comparison tests against H100 (Llama 2 70B)
- Up to 20% more performance in 1v1 comparison tests against H100 (FlashAttention 2)
- Up to 40% more performance in 8v8 server comparison tests against H100 (Llama 2 70B)
- Up to 60% more performance in 8v8 server comparison tests against H100 (Bloom 176B)
Related:
- Benchmark Battle: Core i7 4770K vs i7 14700K Revealed
- Discover Arm Cortex-X925 CPU & Immortalis G925 GPU
- i3 14100F vs i5 12400F: Gaming Benchmarks Revealed
- RTX 4070 Ti SUPER vs RX 6950 XT: How Big’s the Gap?
- Core 2 Quad Q6600 with RTX 4090: Performance Impact?
- DDR4 3600 vs DDR5 6200: Gaming Performance Test Results
- NVIDIA H100 Trains Llama3 40.5B Parameters: 3-Hour Error

Disclaimer: This article is created by the original author. The content of the article represents their personal opinions. Our reposting is for sharing and discussion purposes only and does not imply our endorsement or agreement. If you have any objections, please contact us through the provided channels.