

I am a hard drive, and in our large family, I belong to the mechanical hard drives that locate and read data through mechanical devices. In terms of speed, I can’t compare it with my brother, the SSD hard drive, but I have a larger capacity and I’m cheaper!
Come on, take a picture:

Whether reading or writing data, it must be done through my arm. My arm looks like this, very strong but a bit cumbersome, moving a little slowly. When the operating system asks me to read or write data, I swing my arm to retrieve the data from the disk. Just thinking about this action shows how slow my reading speed is.

If you’re still unclear as to why I’m slow, think about a dining scenario.
Imagine you’re sitting in front of a huge rotating dining table loaded with dishes, all delicious meals, and you’ve spotted your favorite Dongpo pork right across from you, on the inner circle. You stretch out your arm, lift your chopsticks, and “hover” above the inner circle of dishes, then slowly turn the table with your left hand until the Dongpo pork comes in front of you. Then, with the speed of lightning, you quickly pick up the fattest piece and place it on your plate. This is actually how I read data.

My actual structure is much more complex than a dining table. My data is stored on a magnetic disk (platter). This disk is divided into concentric circles (these circles are called tracks), and my data is stored within these concentric circles (tracks).
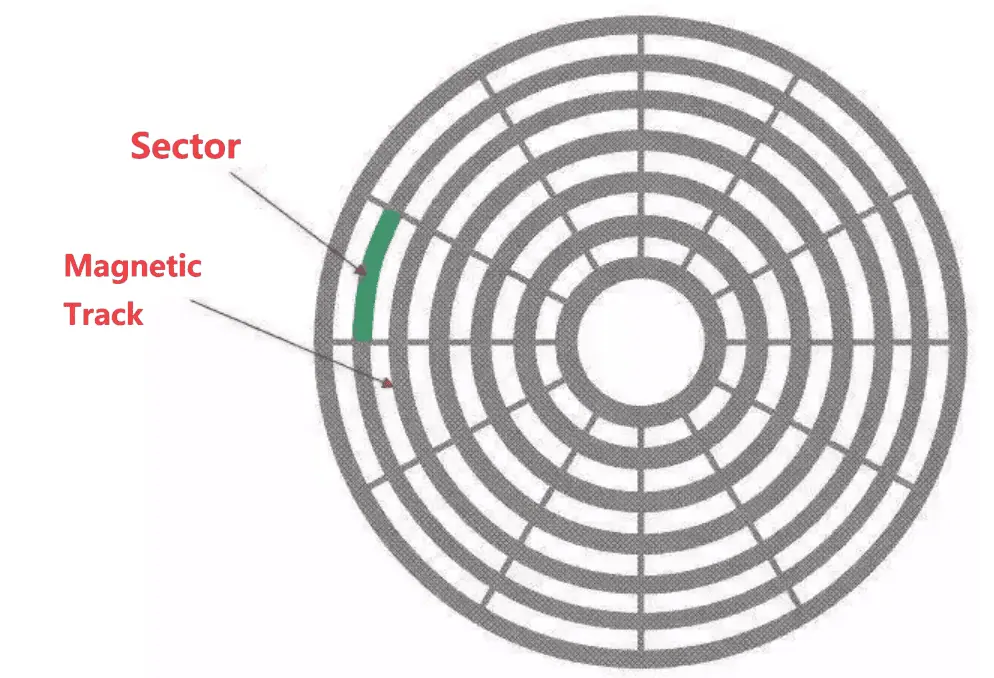
You might understand why mechanical hard drives are so slow because the process of reading (or writing) a piece of data is too complex, thus taking much more time. This time includes seek time (the time to stretch out the arm), rotational delay (the time to turn the dining table), and transfer time (the time to pick up the food).
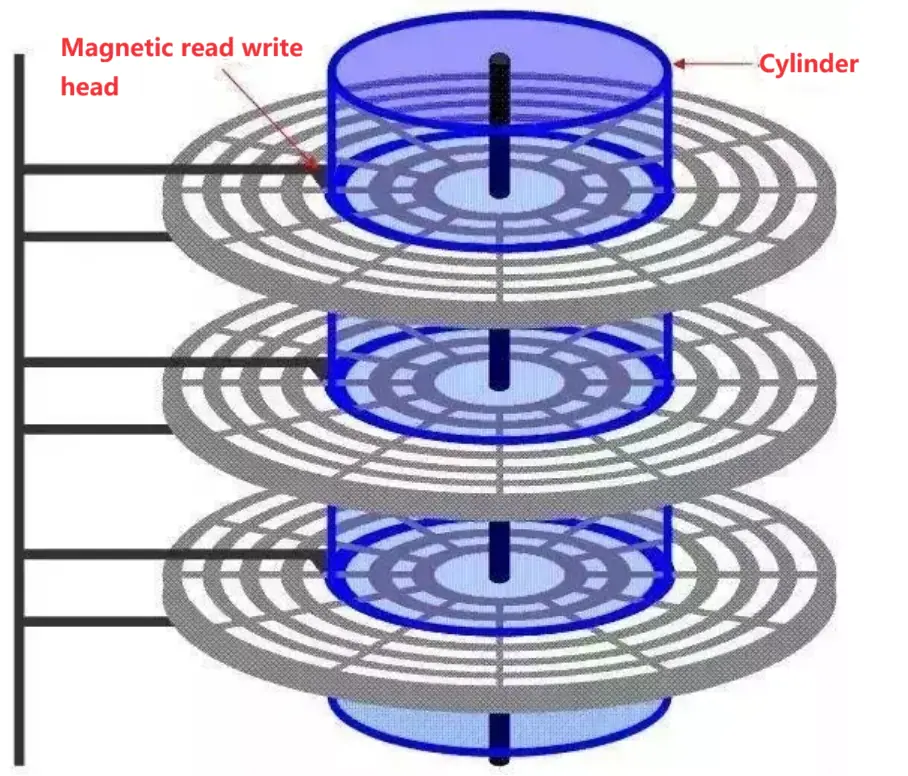
To allow me to store more stuff inside, my inventors stacked multiple disks together, creating the structure below. It’s like converting a single-story house into a multi-story building. Although the area of land used remains the same, it can accommodate more people (store more data).
01
Caching/Buffeting and Request Merging and Reordering
Since I am slow, the operating system has to consider my limitations when it wants to read data.
When upper-layer applications send requests, the operating system doesn’t send them to me immediately for processing but rather accumulates them for a while and sends them to me together once a certain number is reached.
Why accumulate requests? It’s because my arm is too slow to swing back and forth. If it keeps making me retrieve items from the innermost and then the outermost parts, it’s taxing for me.
This method is called caching. After this, the operating system can do more tasks, mainly including request merging and reordering.
Request merging means if a new request can be seamlessly connected to an existing one, it merges these two requests into one.
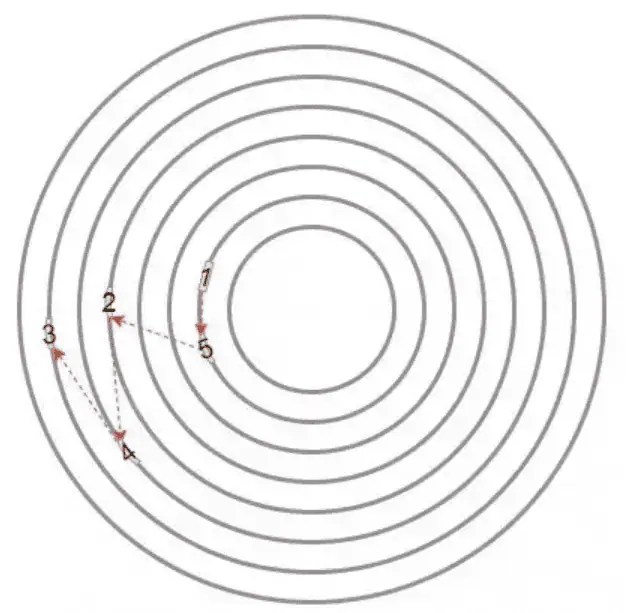
Request reordering involves sorting the requests by logical block addressing (LBA) to ensure they are orderly. For example, if upper-level applications send requests in the time order of 1, 2, 3, 4, and 5, the operating system doesn’t send them to me in this sequence. Instead, it sends them in the sequence indicated by the red dashed arrows in the diagram (1, 5, 2, 4, 3). This way, I don’t have to keep swinging my heavy arm (read/write head) back and forth.
Note: For disks, the seek time is often the longest, so the process usually involves seeking first, and then waiting for the disk to rotate to the desired position before reading data. For example, for a disk spinning at 15,000 RPM, the seek time is typically between 2-8 milliseconds. The average rotational latency is around 2 milliseconds. Therefore, even moving back and forth between two adjacent tracks might exceed 4 ms, so the disk always tries to read all the data on one track before moving to another.
As a food lover, let’s go back to the topic of eating, haha.
It’s like when I want to eat Kung Pao chicken, Beijing shredded pork, and Di San Xian in sequence. Without the caching/buffering mechanism, I would have to turn the table, grab the Kung Pao chicken, and start eating. After finishing, I would look for where the Beijing shredded pork is, then turn the table again, grab the shredded pork, and joyfully eat. I would repeat this process continuously. However, with the caching/buffering mechanism, it’s as if I had planned which dishes I wanted to eat, and then positioned a large scoop at the location where the dishes would rotate. Every time a dish comes to me, I scoop a bit with the scoop, and by the time my arm returns, the scoop has various dishes I want to eat.
02
Final Time Limit
Although the operating system takes great care of my feelings, upper-layer applications might have concerns. For instance, some critical applications might assume a request has failed if there is no response after a long time, leading them to handle it as an error. However, in reality, the request hasn’t failed; it’s just waiting for me to handle other requests.
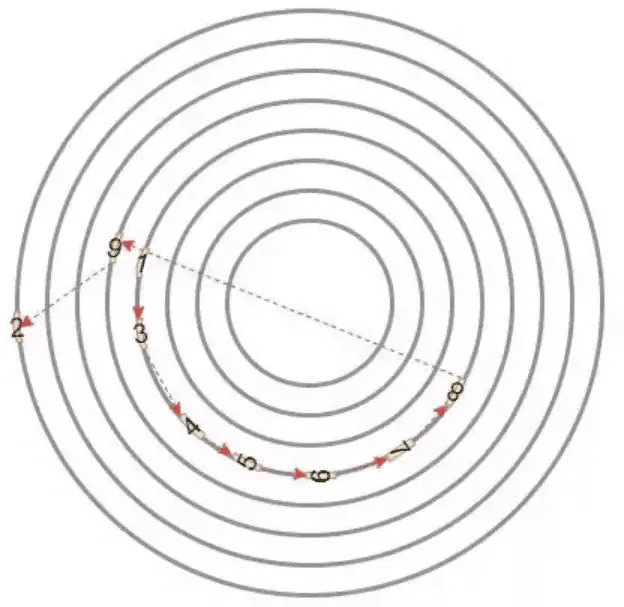
Let’s use an example, still in chronological order: 1, 2, 3, 4, 5, 6, 7, 8, and 9. If we follow the order of logical addresses, then the sequence of handling requests might look like this: 1, 3, 4, 5, 6, 7, 8, 9, and 2.
Request 2 was sent early on, but because it was too far away, it was processed last. If an upper-layer application urgently needs it, this delay would be unacceptable.
To solve the above issue, the operating system has come up with a good solution. This solution involves assigning a deadline to each request and prioritizing the requests that are closest to their deadline.
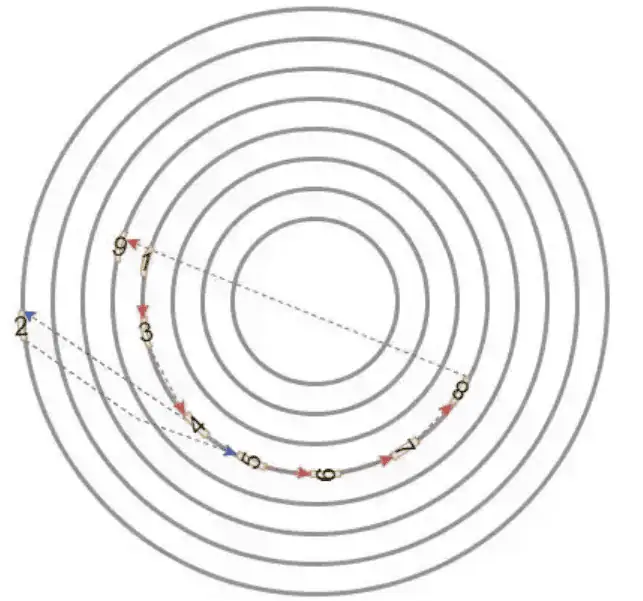
The idea is to record the deadline of each request before it is added to the queue, and use this deadline as the standard for distributing the requests. Continuing with the previous example of ten requests, request 2, being farther away, would be delayed in processing.
During processing, subsequent requests might cause request 2 to be further delayed due to merging and reordering, but because of the deadline, its processing time will not be too late.
03
“Fair” Scheduling
Everyone knows that the operating system runs many applications simultaneously, all working hard to fulfill human needs by sending disk requests to the operating system.
One day, a strange phenomenon occurred: two very diligent applications, Little A and Little B, were constantly sending read and write requests to me through the operating system. However, Little A’s requests were quickly responded to, while Little B’s responses were always delayed, sometimes until the flowers had wilted.
Distressed, Little B asked the operating system, “What’s going on? Why is this so unfair?”
The operating system replied, “Don’t worry, let me communicate with the disk brother and see what’s happening.”
After a thorough investigation, it was found that the data needed by Little A was always near Track 5 and accessed very frequently; whereas Little B’s data was near the distant Track 1000. After the operating system sorted and sent the requests to me, most were from near Track 5.
For me, I do not know to which process the data belongs; I simply process the commands. This led to a problem where Little B’s requests were significantly delayed.
This characteristic of applications always accessing data from a specific area is called data locality, and to address this issue, the operating system implemented another scheduling strategy (CFQ), which considers the fairness among processes.
Simply put: the operating system assigns each process using the disk a request queue and a time slice. Within the time slice allocated by the scheduler, a process can send its read and write requests to the disk. Once a process’s time slice is exhausted, its request queue is suspended, waiting for scheduling.
The duration of each process’s time slice and the length of each process’s queue depend on the process’s I/O priority, which can be categorized into three levels: RT (real-time), BE (best effort), and IDLE (idle). The operating system will consider these factors to determine when a process’s request queue can access the disk.
In other words, the operating system considers the needs of each process when sending requests to me, ensuring that the amount of requests processed for each process is approximately equal.
That concludes today’s introduction of myself and what the operating system has done for me. If there are any unclear areas, please let me know, and I will explain them one by one.
Related:

Disclaimer: This article is created by the original author. The content of the article represents their personal opinions. Our reposting is for sharing and discussion purposes only and does not imply our endorsement or agreement. If you have any objections, please contact us through the provided channels.